AI/ML With Chatbots

Chatbots are created to interact conversationally with humans. They can automate the process of interacting with visitors on the web, on social media platforms and on SMS clients. They can be trained to do specific tasks such as diagnosing ailments or doing financial transactions. Chatbots use NLU or “Natural Language Understanding” to interpret a broad range of natural language dialog exchange by identifying objects such as “context”, “intent” and “entities” mentioned in the conversation. This is achieved by training the “Model”.

In AI/ML, a model replicates a decision process to enable automation and understanding. AI/ML models are mathematical algorithms that are “trained” using data and human expert input to replicate a decision an expert would make when provided that same information. During the training phase the model iteratively processes a large amount of data through one or more statistical algorithms to maximize the accuracy of predicting the probabilistic likelihood of a particular outcome.

In training a model, the number of passes of the entire training dataset the machine learning algorithm has completed is called epochs. Datasets are usually grouped into batches, especially when the amount of data is very large. If the batch size is the whole training dataset then the number of epochs is the number of iterations. For practical reasons, this is usually not the case. Many models are created with more than one epoch. The general relation where dataset size is d, number of epochs is e, number of iterations is I, and batch size is b would be d*e = I*b. Determining how many epochs a model should run is based on many parameters related to both the training data itself and the goal of the model; and often a deep understanding of the data itself is indispensable.
In both the above approaches, the process of training the model varies slightly but the rest of the implementation process mostly remains the same.
While using the first approach to develop the disease diagnosis Chatbot we used the following libraries:
- Spacy: Open source library for advanced Natural Language Processing
- Flask: Light weight Web Server Gateway Interface (WSGI) to create an API wrapper to interact with the Chatbot
- Ktrain : A Deep Learning TensorFlow Keras wrapper to train the Multi-Classification Bidirectional Encoder Representations from Transformers (BERT) model
- Pyttsx3: Text-to-speech conversion library in Python
- SpeechRecognition: A wrapper Library with support for several speech recognition engines and APIs, online and offline
We did not find any dataset in public domain to train the model, possibly due to the strict privacy policies in the healthcare industry, so, we created our own dataset. The dataset consisted of variations of patient-doctor conversations where the patients describe their symptoms and the doctor (our Chatbot) asks leading questions to get more information from the patient until the decision point is reached and the diagnosis is complete. In the absence of expert inputs from a doctor, we trained a text classification model to predict one of the three likely outcomes; the patient has influenza, common cold or neither. We selected influenza and common cold because we were familiar with the symptoms
The model is built on pre-trained BERT which we fine-tuned using our dataset to classify the disease. We chose BERT because it requires less data to train the model. After 12 epochs, the model could predict with an accuracy of 93%.
Using the second approach mentioned above, we built another Chatbot that performs financial transactions such as transfer money to a third party. This was implemented using the WIT.AI framework. For this approach we used the following libraries:
- Flask: Light weight Web Server Gateway Interface (WSGI) to create an API to interact with the Chatbot
- Wit: Python SDK for Wit.ai
- Pyttsx3: Text-to-speech conversion library in Python
- SpeechRecognition: Library for speech recognition, with support for several engines and APIs, online and offline
The model training process was similar to the first approach. We created the text dataset of conversation comprising of multiple ways in which a person would instruct an assistant to transfer money to a third party. The wit.ai framework was used to identify the intent (“transfer money” for example) and the entities such as name of the party, bank account number, amount and currency. Wit.ai is capable of taking either audio or text as input. The training varies based on the type of input. If the input is audio, the framework is trained to identify intent and entities based on utterances. In case of text, it is based on words or phrases, taking into consideration the intent and the context.
Once the JSON response is received from wit.ai, the bot takes further course of action based on the intent and entities. The bot also identifies whether the entity to which the money is to be transferred already exists in the users “payee” list or not and ask questions accordingly to gather additional information if necessary.
We used the AudioContext API of the browser and Recorder.js JavaScript library to capture the audio stream and convert the audio data into WAV format. This is streamed to the server. The SpeechRecognition Python library is a wrapper for several speech recognition engines and APIs. This library takes the WAV stream as input and uses one of the speech recognition engine / APIs to convert speech to text. In these Chatbots we used the Google Speech API.
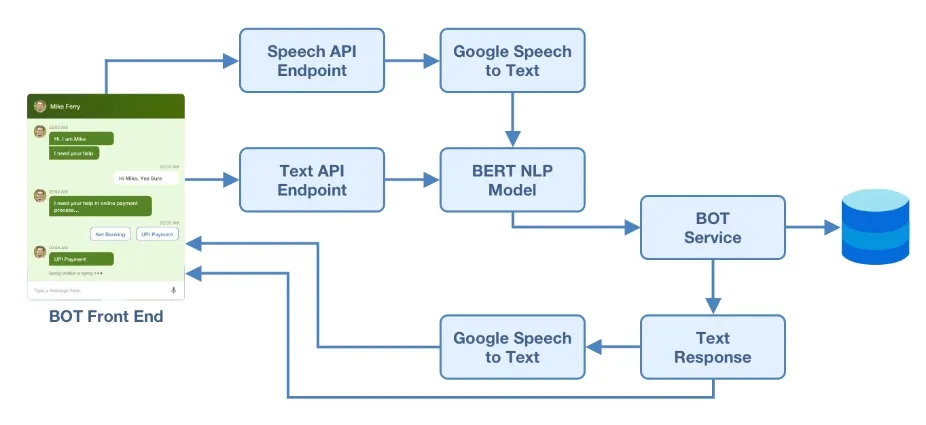
Similarly, the response from the AI Model is in the text form was converted to audio using the pyttsx3 library in Python. This library provides the additional advantage of being able to work offline.
The frontend user interface for these Chatbots was developed in HTML, CSS and JavaScript but the Python code and trained model on the server is independently accessible through the Flask API wrapper, so, the frontend can be developed using any technology.